Bi-Encoder 모델 구조 바이 인코더는 BERT 모델의 출력을 풀링(Pooling)층을 통해 고정된 크기의 문장 임베딩을 생성합니다. BERT 모델은 입력 토큰마다 출력 임베딩을 생성하는데 풀링층을 사용해 문장을 대표하는 1개의 임베딩으로 통합합니다.풀링층을 통해 문장의 길이가 달라져도 1개의 고정된 차원의 임베딩이 반환되기 때문에 코사인 유사도(Cosine Similiary)와 같은 거리 계산 방식을 활용해 두 문장 임베딩 사이의 거리를 쉽게 계산할수 있습니다. AI/LLM 2025.02.09
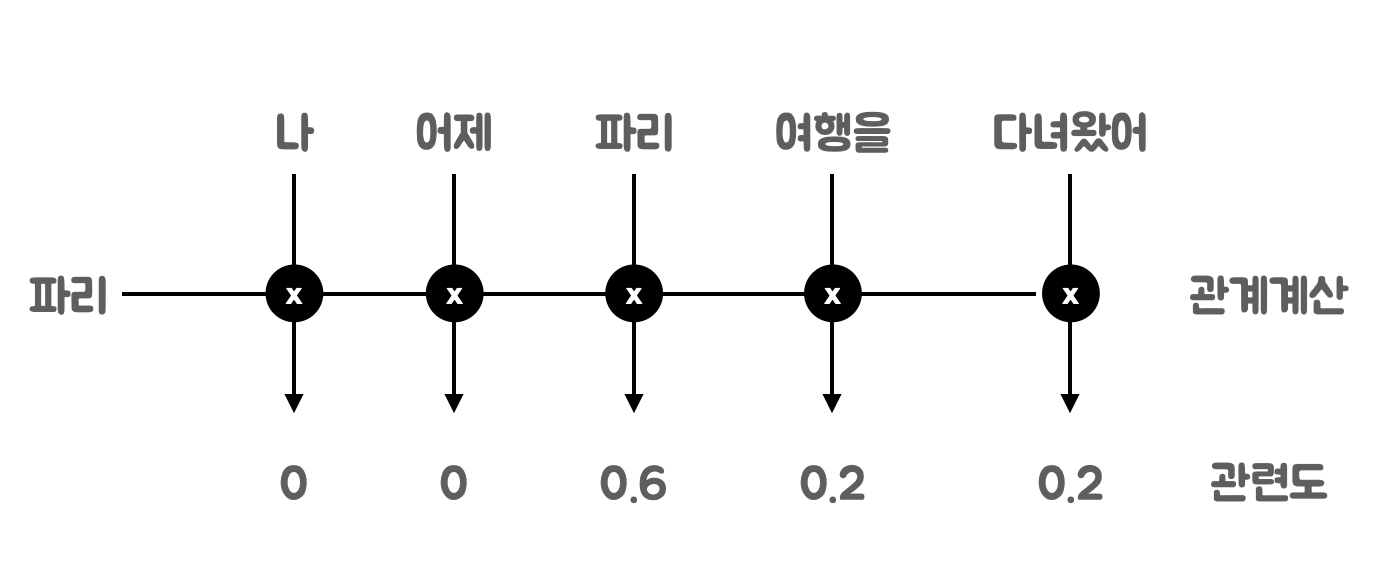
Attention Attention에서의 핵심개념은 query, key, value 이다Attention이라는 개념이 나온 이유는 사람이 단어 사이의 관계를 고민하는 과정을 Deep Learning 모델이 수행할 수 있도록 모방하기 위한 연산 때문이다 1. 단어와 단어 사이의 관계를 계산해서 그 값에 따라 관련이 깊은 단어와 그렇지 않은 단어 를 구분할 필요가 있음2. 관련이 깊은 단어는 더 많이, 적은 단어는 더 적게 맥락에 반영해야 함 Query, Key, Valueex] 나 어제 파리 여행을 다녀왔어여기서 파리는 곤충 파리인가? 프랑스 도시 파리인가?문장의 문맥을 통해 파리가 도시인지 알기 쉬운 키는 '파리', '여행을', '다녀왔어' 이다 '파리'와 관계가 높은 키 값을 찾아야 함Query와 Key 토큰을 토큰 .. AI/LLM 2024.12.01