Attention에서의 핵심개념은 query, key, value 이다
Attention이라는 개념이 나온 이유는 사람이 단어 사이의 관계를 고민하는 과정을 Deep Learning 모델이 수행할 수 있도록 모방하기 위한 연산 때문이다
1. 단어와 단어 사이의 관계를 계산해서 그 값에 따라 관련이 깊은 단어와 그렇지 않은 단어 를 구분할 필요가 있음
2. 관련이 깊은 단어는 더 많이, 적은 단어는 더 적게 맥락에 반영해야 함
Query, Key, Value
ex] 나 어제 파리 여행을 다녀왔어
여기서 파리는 곤충 파리인가? 프랑스 도시 파리인가?
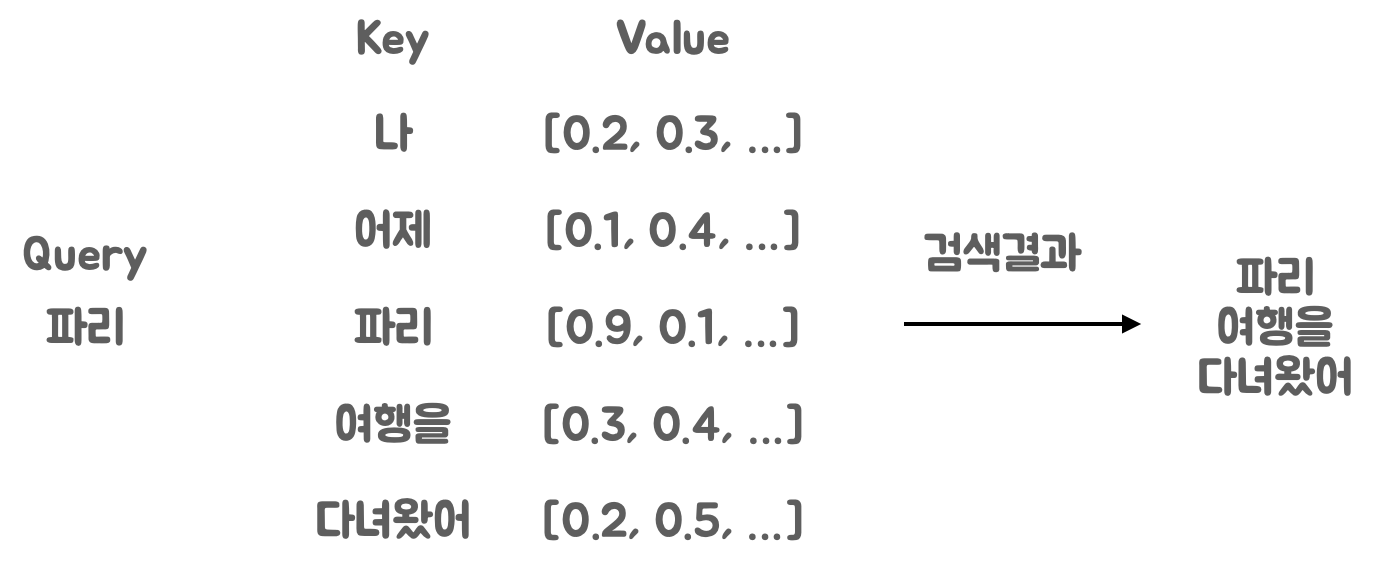
문장의 문맥을 통해 파리가 도시인지 알기 쉬운 키는 '파리', '여행을', '다녀왔어' 이다
'파리'와 관계가 높은 키 값을 찾아야 함
Query와 Key 토큰을 토큰 임베딩으로 변환해 관계를 계산하면 됨

Embedding을 직접 활용해 관련도를 계산하는 방식은 2가지 문제가 존재
1. 같은 단어 끼리는 Embedding이 동일하므로 관련도가 크게 계산되면서 주변 맥락을 충분히 반영하지 못함
2. Token의 의미가 유사하거나 반대되는 경우 처럼 직접적 관련성이 있다면 잘 작동하지만 문법에 의거해 Token이 이어지는 경우처럼 간접적 관련성은 반영이 어려움
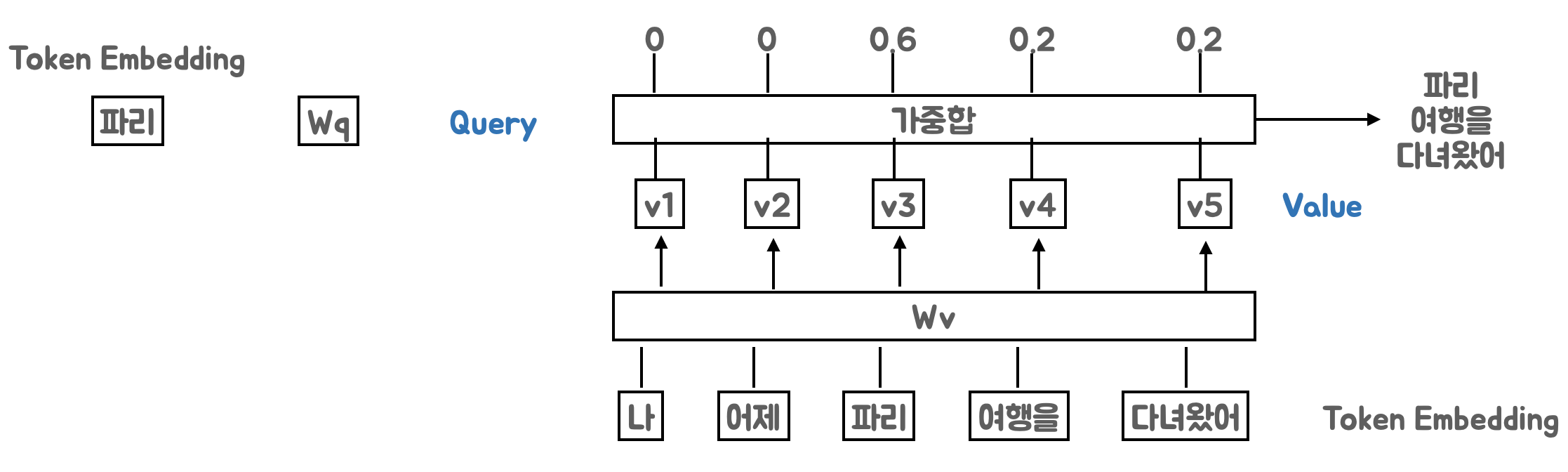
이와 같은 문제를 피하기 위해 Token Embedding을 변환하는 가중치 Wq, Wk를 도입(딥러닝에서는 어떤 기능을 학습하고자 할때 가중치(weight)를 도입하여 학습시켜 이 값을 업데이트 시킴)
Wq, Wk 가중치를 통해 토큰과 토큰 사이의 관계를 계산하는 능력을 학습시킴

Transformer에서는 값(Value)도 Token Embedding을 가중치(Wv)를 통해 변환
3가지 가중치(Wq, Wk, Wv)를 통해 내부적으로 토큰과 토큰 사이의 관계를 계산해서 적절히 주변 맥락을 반영하는 방법을 학습
Attention 연산
Attention 연산에는 여러 방식이 존재하나 그 중 스케일 점곱 방식이 존재
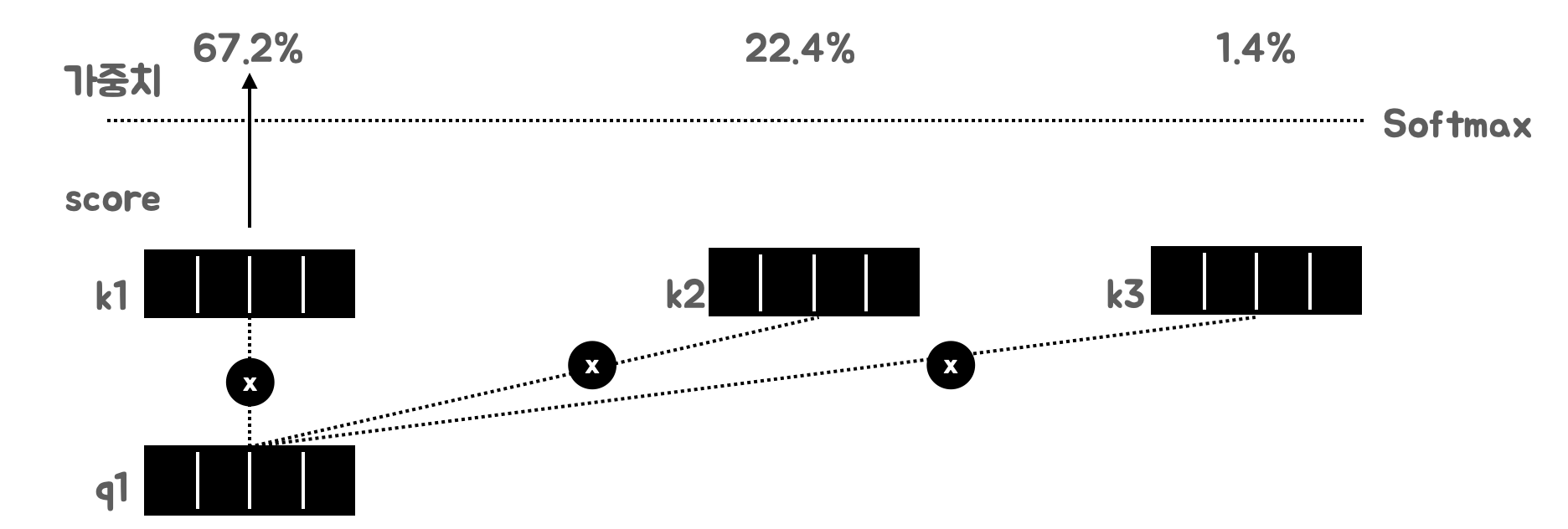
1. Query와 Key를 곱한다, 분산이 커지는 것을 방지하기 위해 임베딩 차원 후(dim_k)의 제곱근으로 나눈다
2. Query와 Key를 곱해 계산한 score를 합이 1이 되도록 Softmax를 취해 가중치로 변환
3. 가중치와 값을 곱해 입력과 동일한 형태의 출력을 반환
각 Vector를 가중합해서 새로운 단어 벡터생성
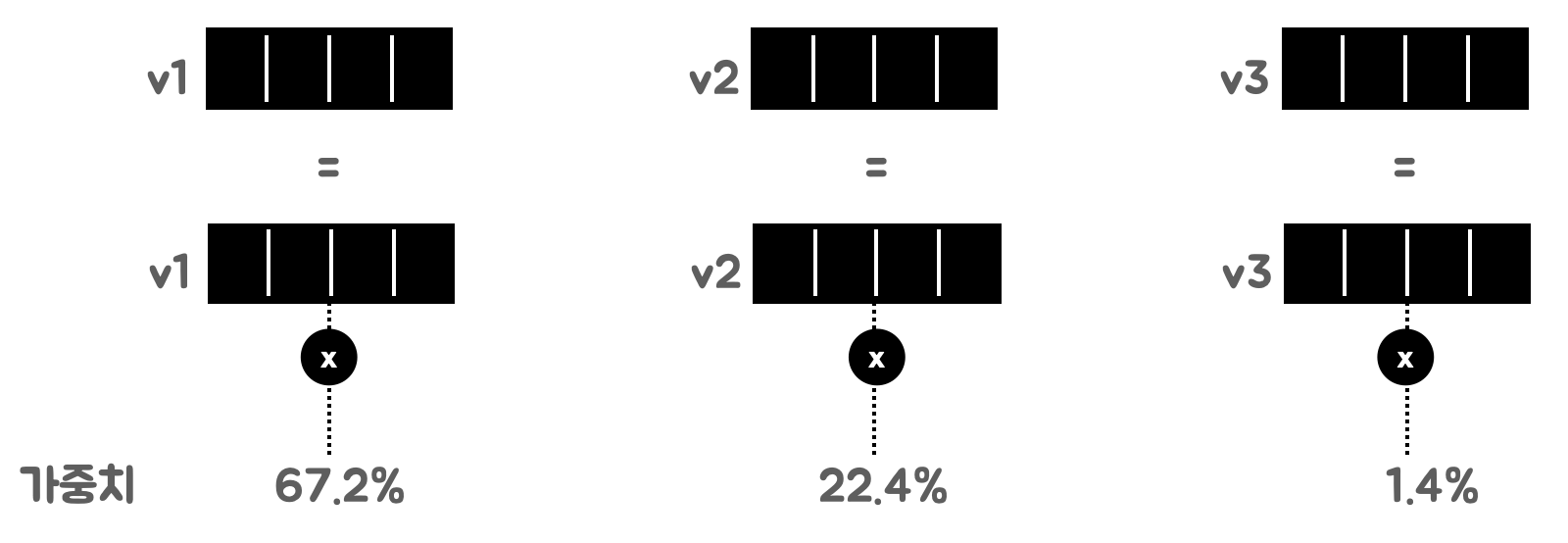
가중치와 값을 곱해 입력과 동일한 형태의 출력을 반환
Attention을 거치고 나면 입력과 형태는 동일하면서 주변 토큰과의 관련도에 따라 값 벡터를 조합한 새로운 Token Embedding이 생성
'AI > LLM' 카테고리의 다른 글
| Bi-Encoder 모델 구조 (0) | 2025.02.09 |
|---|---|
| 문장 사이 관계를 계산하는 방법 Bi-Encoder vs Cross-Encoder (0) | 2025.02.08 |
| [Prompt] 역할 지정 Prompt 작성방법 (10) | 2025.01.02 |
| RAG Pipeline과 LlamaIndex, LangChain 간략소개 (2) | 2024.11.25 |