k-최근접 이웃 분류(k-nearest neighbor classifier)는 지도학습으로 데이터를 가장 가까운 유사 속성에 따라 분류하는 방법
데이터로부터 거리가 가까운 K개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘(거리 측정엔 유클리드 거리 계산법을 사용)
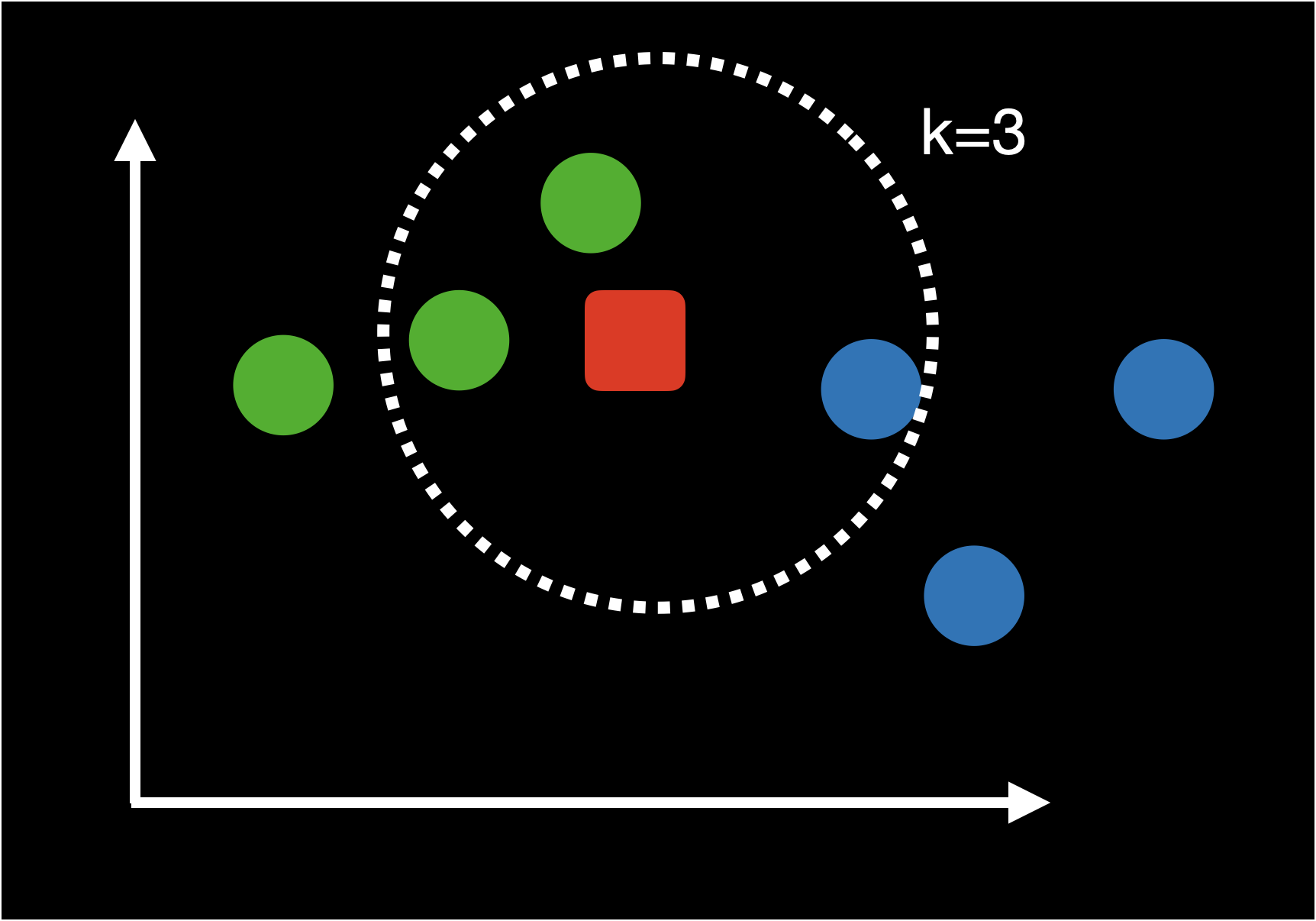
판별하고 싶은 데이터와 인접한 k개수의 데이터를 찾아 해당 데이터의 라벨이 다수인 범주로 데이터를 분류하는 방식으로 k의 개수는 홀수를 선호하는데 짝수인 경우엔 동점이 발생할 확률이 존재하기 때문
반응형
'AI > MachineLearning' 카테고리의 다른 글
| [비지도 학습]k 평균 군집화 (0) | 2021.10.28 |
|---|